自己情報量とは, ある一つの事象が起きたとき, その事象がどれほど起こりにくいかを表す尺度である.
自己情報量 I(A) は, 事象 A の起きる確率 P(A) を用いて次のように定義される :
I(A)=−log2P(A)
直感的には, 「ほとんど起こらない珍しい事象が起きたときに, 多くの情報量が得られる」と考えられる.
相互情報量とは, 二つの情報量 X,Y が互いにどれだけ影響し合っているか(相互に共有しているか)を表す尺度であって, 各事象の確率の積と, それらの同時確率の比を用いて次のように定義される :
I(X;Y)=EP(x,y)[−log2P(x,y)P(x)P(y)]=−x∈X∑y∈Y∑P(x,y)log2P(x,y)P(x)P(y)=x∈X∑y∈Y∑P(x,y)log2P(x)P(y)P(x,y)
2行目から3行目の式変形では, 対数の分子・分母の交換によって符号が反転していることに注意.
また、二つの事象 X,Y 間に依存関係がないとき, P(x,y)=P(x)P(y) となり, I=0 で最小値を取る.
エントロピーとは, 確率変数の各値の自己情報量の期待値として定義され, 平均情報量とも呼ばれる.
具体的には, 確率変数 X のエントロピー H(X) は, 以下のように表される :
H(X)=−x∈X∑P(x)log2P(x)
確率変数は連続でもよく, その場合は ∑ を ∫ に置き換えることで計算できる.
また, 確率分布が一様である場合にエントロピーは最大となる.
条件付きエントロピーとは, ある確率変数 Y が既知である下で, 新たに確率変数 X について知ったときに得られる情報量の期待値として定義される :
H(X∣Y)=EP(x,y)[I(X∣Y)]=x∈X∑y∈Y∑P(x,y)I(x∣y)=−x∈X∑y∈Y∑P(x,y)log2P(x∣y)
また、 H(X) を事前エントロピー, H(X∣Y) を事後エントロピーとしたとき, 両者の差分である H(X)−H(X∣Y) は, 確率変数 Y によって得られる X についての情報量の期待値を表し, これは相互情報量 I(X;Y) と等しい :
H(X)−H(X∣Y)=I(X;Y)
証明 (クリックで展開)
H(X)−H(X∣Y)=−x∈X∑P(x)log2P(x)+x∈X∑y∈Y∑P(x,y)log2P(x∣y)=−x∈X∑y∈Y∑P(x,y)log2P(x)+x∈X∑y∈Y∑P(x,y)log2P(x∣y)=x∈X∑y∈Y∑P(x,y)log2P(x)P(x∣y)=x∈X∑y∈Y∑P(x,y)log2P(x)P(y)P(x,y)=I(X;Y)■
ここで, 1行目から2行目の変形に, 周辺確率の性質 : P(x)=y∈Y∑P(x,y) を用いた.
結合エントロピーとは, 二つの確率変数 X,Y の同時分布に基づくエントロピーとして定義される :
H(X,Y)=−x∈X∑y∈Y∑P(x,y)log2P(x,y)
また、以下のような関係式が成り立つ :
H(X,Y)=H(X)+H(Y)−I(X;Y)
証明 (クリックで展開)
H(X,Y)=H(X)+H(Y)−I(X;Y)=−x∈X∑P(x)log2P(x)−y∈Y∑P(y)log2P(y)−x∈X∑y∈Y∑P(x,y)log2P(x)P(y)P(x,y)=−x∈X∑y∈Y∑P(x,y)log2P(x)−x∈X∑y∈Y∑P(x,y)log2P(y)−x∈X∑y∈Y∑P(x,y)(log2P(x,y)−log2P(x)−log2P(y))=−x∈X∑y∈Y∑P(x,y)log2P(x,y)■
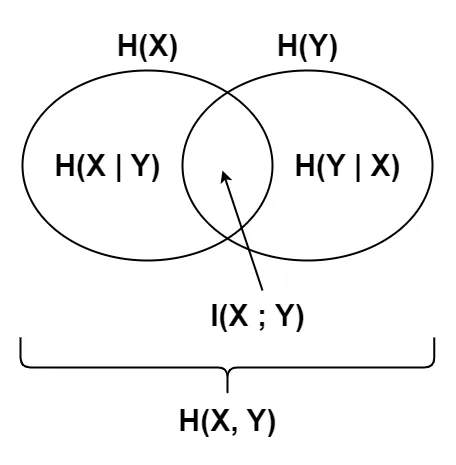 エントロピーの関係図
エントロピーの関係図
クロスエントロピーとは, ある確率分布 Q(X) が基準となる確率 分布 P(X) からどれだけ離れているかを表す尺度であり, 次のように定義される :
H(P,Q)=−x∈X∑P(x)log2Q(x)
P(X)=Q(X) のとき, クロスエントロピーは最小になる.
KLダイバージェンスは相対エントロピーとも呼ばれており, クロスエントロピーと同様に, ある確率分布 Q(X) が基準となる確率分布 P(X) からどれだけ離れているかを表す尺度であり, 次のように定義される.
DKL(P∣∣Q)=∫xP(x)log2Q(x)P(x)dx
これは, 各事象に対する確率分布間の情報量の差の期待値として解釈できる.
KLダイバージェンスは対称性を持たないことに注意すること.
DKL(P∣∣Q)=DKL(Q∣∣P)また, KLダイバージェンスは, クロスエントロピーとエントロピーの差に分解できる :
DKL(P∣∣Q)=∫xP(x)log2Q(x)P(x)dx=−∫xP(x)(log2Q(x)−log2P(x))dx=−∫xP(x)log2Q(x)dx−(−∫xP(x)log2P(x)dx)=H(P,Q)−H(P)
さらに, 相互情報量は, 同時確率分布から見た二つの確率分布の積とのKLダイバージェンスとして表せる :
I(X;Y)=DKL(P(x,y)∣∣P(x)P(y))
KLダイバージェンスには, 対称性を持たなかったり, P(x)=0,Q(x)=0 の領域で値が不定になったりするなどの問題点があった.
そのため, KLダイバージェンスの平均を取って対称化・平滑化を行ったものがJSダイバージェンスであり, 次のように定義される.
DJS(P∣∣Q)ただし, M=21DKL(P∣∣M)+21DKL(Q∣∣M)=21(P+Q)(P, Qの混合分布)
JSダイバージェンスは, 次の特徴を持つ.
- 常に 0 以上 1 以下の値を取り, P=Q のときにのみ 0 となる.
- 平滑性 : 極端な確率の差に対して穏やかな反応を示す.
- 対称性 : DJS(P∣∣Q)=DJS(Q∣∣P) が成り立つ(分布の順序に依存しない).
- 有界性 : 常に有限の値を取る.




