【E資格対策】リカレントニューラルネットワーク
リカレントニューラルネットワーク(RNN)
系列データに対応した, 再帰的な構造御持つニューラルネットワーク. その時点の入力と, ひとつ前のモデルの状態を入力として, 新たな出力を作成する.
長い系列におけるRNNの勾配消失問題が起こりやすいという問題がある.
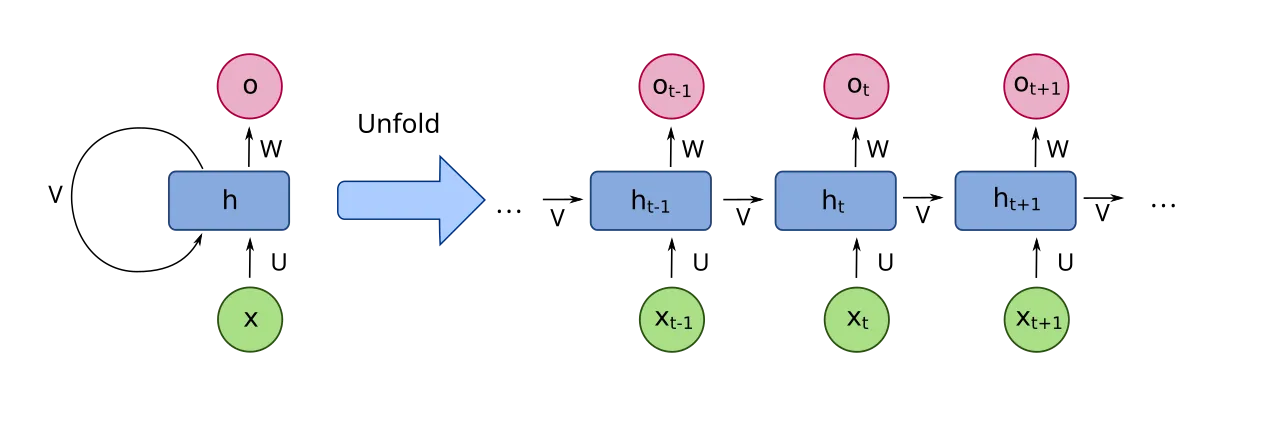
Wikipediaより引用 | fdeloche - 投稿者自身による著作物, CC 表示-継承 4.0, リンクによる
順伝播の計算
順伝播の更新式は以下のようになる.
ここで, は時間ステップであり, は入力ベクトル, は隠れ層のベクトル, は出力ベクトル, は入力から隠れ層への重み行列, は隠れ層から隠れ層への重み行列, は隠れ層から出力への重み行列, は隠れ層のバイアスベクトル, は出力のバイアスベクトル, は隠れ層の活性化関数, は出力の活性化関数である.
逆伝搬の計算(Backpropagation Through Time; BPTT)
BPTT法は, 時系列データに対応するため, 時間ステップを考慮した誤差逆伝播法である.
双方向RNN
時系列データの先行情報と後続情報を同時に処理できるため, 過去と未来の両方の文脈を考慮することが可能. 特に文脈の理解や翻訳などのタスクに有効.
順方向と逆方向の状態は, 計算グラフ上で接続されていないことに注意.
LSTM
RNNでは, 勾配消失問題から長期的な系列データに対する予測が難しいことが課題であった. そのため, メモリセルという構造を取り入れて, 長期的な依存関係を学習できるようにしたのがLSTM(Long Short-Term Memory)である.
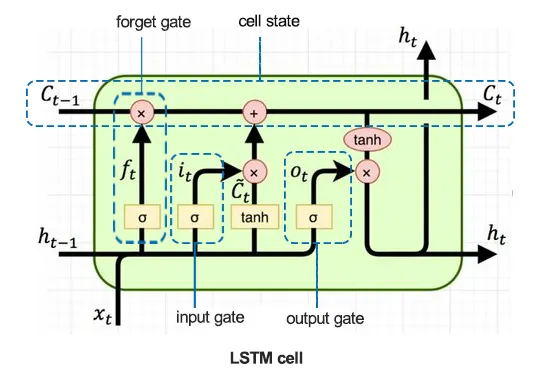
データサイエンスと機械学習(第26回):時系列予測における究極の戦い - LSTM対GRUニューラルネットワーク より引用
※ 関数は主にメモリセルの状態の更新や出力値の計算に, シグモイド関数は主にゲートの制御に用いられる.
メモリセル
メモリセルは, LSTMにおいて長期的な情報を保持するための構造で, 順伝播の過程で選択された情報を加算し続けることで, 長期的な依存関係を学習できるようにする.
入力ゲート(Input Gate)
全ての情報をメモリセルに書き加えると, メモリセルが過剰に情報を保持してしまう可能性があるため, 書き加える情報を入力から制御できるようにする.
ゲートにはシグモイド関数が用いられる.
出力ゲート(Output Gate)
次の時間ステップにどれだけの情報を伝えるかを入力から制御できるようにする.
ゲートにはシグモイド関数が用いられる.
忘却ゲート(Forget Gate)
不要な情報をメモリセルから一気に削除するためのゲート. 劇的なパターン変化に柔軟に対応できるようになる.
ゲートにはシグモイド関数が用いられる.
GRU(Gated Recurrent Unit)
GRUは, LSTMにおける計算効率の問題を改良したモデルで, ゲートをリセットゲートと更新ゲートの2つに簡略化している. また, メモリセルを廃止し, モデルの状態のみを次の予測に渡している.
ただし, 長期的な問題ではLSTMに劣る場合がある.
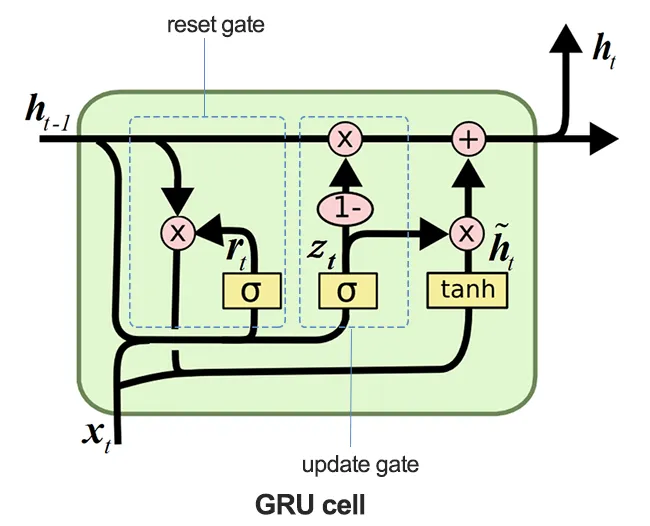
データサイエンスと機械学習(第26回):時系列予測における究極の戦い - LSTM対GRUニューラルネットワーク より引用
更新ゲート(Update Gate)
ひとつ前の状態と現時点の入力を合わせて, 現時点の状態をどれだけ更新するかを決定する.
ゲートにはシグモイド関数が用いられる.
リセットゲート(Reset Gate)
ひとつ前の状態と現時点の入力を合わせて, 過去の情報をどれだけリセットして次の状態に引き継ぐかを決定する.
ゲートにはシグモイド関数が用いられる.
Seq2Seq(Sequence to Sequence)モデル(エンコーダ-デコーダモデル)
入力された系列データから, 系列データ全体が示す意味(隠れ状態ベクトル)を取り出し, それらを用いて別の系列データに変換する. このとき, 隠れ状態ベクトルを取り出すモデルをエンコーダ, 隠れ状態ベクトルから別の系列データで表現するモデルをデコーダという.
Seq2Seqの重要な特徴として, エンコーダからデコーダへの情報伝達が固定次元のベクトルとして行われる点が挙げられる. エンコーダやデコーダはそれぞれ異なる役割を果たすものの, 構造はRNNやLSTMと一般的には同じである. ただし, エンコーダとデコーダが扱うパラメータ数(次元数)を可変にすることはできない.
Attention機構
Seq2Seqモデルは, 長い系列データに対しては性能が低下しやすいことが指摘されている. これを解決するため, 系列データの各要素が出力にどのように影響を与えるかを考慮し, 重要な情報を適切に強調するAttention機構が提案された.
Attention機構付きのSeq2Seqモデル
エンコーダとデコーダはそのままにAttention機構を追加し, 全ての隠れ状態ベクトルをAttention機構に保存してデコーダに渡している.
ある隠れ状態から次の状態を生成する手順は以下の通りである.
エンコーダ:
- 各時間ステップのデータを入力し, 隠れ状態ベクトルを作成.
- エンコーダが系列全体を処理した後に, Attention機構を通じて得られた出力ベクトルをデコーダに渡す.
デコーダ:
- Attention機構によって重み係数を算出し, 隠れ状態ベクトルを加工する.
- Attention機構によて重みづけされた毎時点それぞれの隠れ状態ベクトルを, 一つ前の時間ステップにおける状態と入力と組み合わせて, 次時点におけるデータの予測確率を出力する.




